
Rozdział I. Informacje ogólne
1. Czym jest RxJava 3?
RxJava to implementacja w Javie standardu Reactive Extensions (ReactiveX), który służy do tworzenia reaktywnych programów, czyli asynchronicznych, opartych na zdarzeniach przy użyciu obserwowalnych sekwencji. Jego istotą jest rozszerzenie wzorca projektowego o nazwie Observer, aby obsługiwać sekwencje danych lub zdarzenia oraz dodać operatory, które pozwalają na składanie sekwencji danych w sposób deklaratywny, jednocześnie usuwając problemy wątków na niskim poziomie, synchronizacji, bezpieczeństwa wątków i współbieżnej struktury danych.
Użycie RxJava jest nazywane funkcjonalnym reaktywnym programowaniem, jednakże jest to błędne określenie, choć biblioteka jest funkcjonalna i reaktywna. Różnica wynika z tego, że funkcjonalne reaktywne programowanie działa na wartościach, które zmieniają się ciągle, podczas gdy RxJava operuje o dyskretnych wartościach, które są udostępniane w przeciągu określonego czasu.
Reaktywne programowanie to specyfikacja, której celem jest zarządzanie asynchronicznymi strumieniami, dostarczaniem narzędzi, łączenie strumieni i zarządzanie kontrolą przepływu danych. Z punktu widzenia reaktywnego programowania wszystko jest strumieniem. Podstawową klasą tutaj jest klasa Observable, która reprezentuje strumień. Obserwowalny mechanizm oferowany przez RxJava 3 pozwala na traktowanie strumieni asynchronicznych zdarzeń tak samo prosto jak tablice z danymi. Zwalnia to programistę z obsługi metod zwrotnych, co czyni kod bardziej przejrzystym i mniej podatnym na błędy.
2. Jak działa wzorzec projektowy Observer?
Wzorce projektowe (design patterns) to uniwersalne, sprawdzone w praktyce rozwiązanie często pojawiających się, powtarzalnych problemów projektowych. Pokazują powiązania i zależności pomiędzy klasami oraz obiektami i ułatwiają tworzenie, modyfikację, a także utrzymanie kodu źródłowego.
Observer jest wzorcem, w którym obiekt, przechowuje listę swoich zależności, zwanych obserwatorami (observers), i powiadamia je automatycznie o jakiejkolwiek zmianie stanu, zazwyczaj poprzez wywołanie jednej z ich metod. Wzorzec ten służy głównie do wdrażania rozproszonych systemów obsługi zdarzeń, w oprogramowaniu sterowanym zdarzeniami. W tych systemach podmiot jest zwykle nazywany „strumieniem zdarzeń” lub „strumieniowym źródłem zdarzeń”, podczas gdy obserwatorów nazywa się „naczyniami zdarzeń”. Nazewnictwo strumieni nawiązuje do fizycznej konfiguracji, w której obserwatorzy są fizycznie oddzieleni i nie mają kontroli nad emitowanymi zdarzeniami od podmiotu (źródła strumienia). Ten wzorzec doskonale pasuje do każdego procesu, w którym dane przychodzą z niektórych danych wejściowych, które nie są dostępne dla procesora podczas uruchamiania, ale zamiast tego przychodzą losowo (żądania HTTP, dane I/O, dane wejściowe użytkownika z klawiatury, rozproszone bazy danych i blockchain). Chociaż nie jest to obowiązkowe, większość implementacji wzorca Observer wykorzystuje nasłuchujące w tle wątki.
Wzorzec Observer rozwiązuje kilka problemów:
— Umożliwienie lekkiego powiązania między zależnościami o charakterze jeden-do-wielu.
— Zapewnienie automatycznej aktualizacji informacji o zmianie stanu wielu zależnym obiektom.
Dla zobrazowanie wzorca Observer poniżej przykład klasy NetManager:
public class NetManager{
private String port;
private List<Channel> channels = new ArrayList<>();
public void addObserver(Channel channel){
this.channels.add(channel);
}
public void removeObserver(Channel channel){
this.channels.remove(channel);
}
public void setPort(String port){
this. port = port;
for (Channel channel: this.channels){
channel. updatePort(this. port);
}
}
}
która może informować zarejestrowane kanały w postaci klas Channel:
public class Channel{
private String port;
public void updatePort (Object port){this. port = port; }
}
o bieżącym porcie:
NetManager observable = new NetManager ();
Channel observer = new Channel ();
observable.addObserver(observer);
observable.setPort(„110”);
3. Czym jest reaktywne programowanie?
Programowanie reaktywne to wzorzec programowania asynchronicznego zajmujący się strumieniami danych i propagowaniem informacji o ich zmianach, którego celem jest ułatwianie wyrażania statycznych lub dynamicznych strumieni danych za pomocą danego języka programistycznego.
Zaletami reaktywnego programowania jest:
— Eliminacja funkcji zwrotnych.
— Ułatwienie pracy z asynchronicznym kodem.
— Lepsze zarządzanie błędami.
— Ułatwienie pracy z wątkami.
— Łatwiejsze tworzenie skalowanie.
— Ułatwienie łączenia strumieni.
— Tworzenie bardziej przejrzystego kodu.
Z kolei do wad reaktywnego programowania można zaliczyć:
— Kosztowność pod względem pamięci.
— Stroma krzywa uczenia się.
— Tworzenie bardziej skomplikowanego kodu.
— Brak dokumentacji.
Z jednej strony funkcjonalne programowanie jest procesem budowania oprogramowania poprzez składanie ze sobą funkcji, unikania stanów i zmiennych danych. Z drugiej strony reaktywne programowanie jest paradygmatem asynchronicznego programowania zajmującym się strumieniami danych i propagowaniem zmian. Razem funkcjonalne reaktywne programowanie formuje kombinacje funkcjonalnych i reaktywnych technik, które stanowią eleganckie podejście do programowania opartego o zdarzenia.
4. Co jest podstawą działania RxJava 3?
RxJava 3 oparta jest na dwóch podstawowych klasach Observables i Observers. Klasa obserwowalna (Observable) jest wykorzystywana do emitowania elementów, a klasa obserwatora (Observer) do ich konsumpcji. Obiekty obserwatorów rejestrują się w obiekcie obserwowalnym, a ten następnie wywołuje z obiektu obserwatora metodę onNext() dla przeprowadzenia konsumpcji, onError() w celu zawiadomienia o błędzie lub onCompleted() gdy operacja się zakończy. W relacji z obserwatorami klasy obserwowalne są źródłami danych. Przeważnie zaczynają dostarczać dane od razu po tym, jak obserwator zacznie nasłuchiwać. Obiekt obserwowalny może wyemitować dowolną liczne elementów i mieć dowolną liczbę zarejestrowanych obserwatorów.
Wsparciem dla klas obserwowalnych i obserwatorów są operatory (Operators), które służą do tworzenia obiektów obserwowalnych (timery, zakresy), transformowania (mapowanie, buforowanie, grupowanie, skanowanie), filtrowania (selekcjonowanie, odróżnianie, opuszczenia) i kombinowania (kompresowanie, łączenie). Uzupełnieniem są także harmonogramy (Schedulers). Są to mechanizmy pozwalające na łatwe dodawanie wielowątkowości do obiektów obserwowalnych i obserwatorów posługując się metodami subscribeOn() i observeOn().
5. Jakie pojęcia pojawiają się przy pracy z RxJava 3?
RxJava 3 zajmuje się przepływem danych między źródłem a konsumentem z wykorzystaniem pośredniczących obiektów, dlatego można spotkać takie pojęcia jak przesył zgodnie z prądem (downstream), gdy dane przesyłane są od źródła do konsumenta lub pod prąd (upstream) gdy dane przesyłane są w odwrotnym kierunku. Samo poruszanie się danych w określonym kierunku może być nazywane emitowaniem (emission), a dane mogą być nazywane emisją, elementami, zdarzeniami, sygnałami lub wiadomościami.
Gdy dane przepływają przez pośredników w sposób asynchroniczny, każdy krok może wykonywać inne czynności z różną prędkością. Aby uniknąć tymczasowego buforowania lub pomijania danych stosuje się technikę ciśnienia zwrotnego (backpressure), która jest formą kontroli przepływu, gdzie wspomniane kroki mogą komunikować, ile zostało im elementów do przetworzenia. To pozwala ograniczyć zużycie pamięci, w sytuacjach gdy poszczególne pośrednie elementy nie są w stanie wiedzieć, ile elementy znajdujące się pod prąd wyślą do nich.
6. Jakie są zalety wykorzystania RxJava 3?
Zaletami RxJava 3 są przede wszystkim zalety samego reaktywnego programowania. Wskazać tu trzeba w szczególności zarządzania metodami zwrotnymi i tym samym eliminację koniczności budowania warstw metod zwrotnych, które muszą być jakoś zsynchronizowane. Poza tym RxJava 3 będąc jednowątkowy, posiada narzędzia za tworzenia i zarządzania wątkami za pomocą operatorów i harmonogramów. W pracy z Androidem RxJava 3 pomaga też w obsługiwaniu błędów, które mogą pojawić się w tle. Jeżeli chodzi o zarządzanie kodem, RxJava 3 pomaga uprościć kod przez umożliwienie określenia celów zamiast instrukcji dla aplikacji. Uproszczenie kodu umożliwia jego większą elastyczność. Odbywa się to też za pomocą wachlarza operatorów, dzięki którym można filtrować, łączyć i transformować dane. Na końcu należy wspomnieć, że biblioteka RxJava 3 została zaprojektowana aby dać kontrolę nad zarządzaniem szerokiego zakresu danych w czasie rzeczywistym, co sprzyja tworzenie responsywnych aplikacji.
7. Jakie są konkurencyjne frameworki wobec RxJava 3?
Istnieje wiele implementacji standardu Reactive Extensions (ReactiveX), a także niezależnych bibliotek obsługujących reaktywne programowanie. Jedną z popularniejszych jest LiveData. Jest to reaktywne rozwiązanie zajmujące się dostarczaniem zdarzeń do interfejsu użytkownika w Androidzie. Jej zaletą jest prostota i wsparcie przez Google. Do wad zaliczyć należy działanie jedynie w głównym wątku oraz brak operatorów do łączenia strumieni danych.
Inną biblioteką jest Coroutines stworzona przez JetBrains i związana ściśle z Kotlinem. Ideą stojącą za Coroutines są zadania uruchamiane w lekkich wątkach zwanych korutynami. Zaletami Coroutines jest łatwość uczenia się i możliwość wykorzystania w wieloplatformowaych projektach. Z kolei do wad zaliczyć należy mała ilość zastosowań w praktyce oraz ścisłe powiązanie z Kotlinem.
Na końcu warto wspomnieć o mechanizmie opracowanym przez Goodle o nazwie Work Manager. To API, które pomaga zaplanować asynchroniczne zadania. Work Manager jest rekomendowany do zarządzania zadaniami, które mają działać w tle.
Na tym tle RxJava 3 to biblioteka o bardzo szerokich możliwościach, jednak czasami może okazać się zbyt dużą do prostych projektów.
8. Jaka jest relacja RxJava 3 do poprzednich wersji?
Obecnie najnowszą i jedyną wspieraną wersją biblioteki jest ta z numerem 3. Z kolei wersja 2 zakończyła działanie, wraz ze wsparciem, aktualizacjami i utrzymaniem, w lutym 2021 r. na wersji 2.2.21. Wersja 1 zakończyła działanie w marcu 2018 na numerze 1.3.8. Kolejne wersje RxJava stanowią jedynie jej usprawnienia i nie należy do nich wracać, chyba że zaistnieje konieczność zajęcia się przestarzałym kodem.
Kluczowe zmiany w wersji 3 to:
— Wymaganie Javy 8.
— Wsparcie dla klas Streams, Stream Collectors, Optional, CompletableFeature.
— Usunięcie wsparcia dla klas Duration i pakietu java. util. function.
— Jedna zależność — Reactive-Streams.
— Wsparcie dla wykonania asynchronicznego i synchronicznego.
— Wsparcie dla testowania przez rozbudowane klasy testowe.
— Zmiany w zachowaniu: przetwarzanie wszystkich błędów, zamiany wyjątków przy walidacji parametrów.
— Zmiany API — nowy typ Suplier, zamiany konwerterów, zmiany nazwy metod.
9. Na jakiej licencji działa RxJava 3?
RxJava 3 działa na licencji Apache License w wersji 2.0. W dużym skrócie pozwala ona na używanie, modyfikowanie i redystrybucję programu w postaci źródłowej lub binarnej bez obowiązku udostępnienia kodu źródłowego. Oznacza to, że kod na tej licencji można włączyć do zamkniętych programów — pod warunkiem zachowania zgodności z warunkami tej licencji.
10. Gdzie można znaleźć kod źródłowy RxJava 3?
RxJava 3 posiada ogólnie dostępny kod na GitHubie pod tym adresem:
https://github.com/ReactiveX/RxJava
Gdzie można znaleźć dokumentację RxJava 3?
Tutaj dostępny jest mały tutorial po angielsku:
http://reactivex.io/tutorials.html
Pełna dokumentacja dla wersji 3 znajduje się tutaj:
http://reactivex.io/RxJava/3.x/javadoc/snapshot/
http://reactivex.io/RxJava/javadoc/rx/Single.html
Rozdział II. Instalacja i implementacja
1. Jakie biblioteki są wymagane do pracy z RxJava 3?
W celu utworzenia projektu dla RxJava można posłużyć się środowiskiem Eclipse i Gradle. Należy założyć, że są one poprawnie zainstalowane i skonfigurowane. Zamiast Eclipsa można bez większych problemów wykorzystać środowisko IntelliJ. W Eclipsie utworzymy nowy projekt Java o nazwie RxJavaProj:
File -> New -> Gradle -> Gradle Project
Wybieramy opcję Gradle Wrapper. W utworzonym katalogu o nazwie RxJavaProj znajduje się plik o nazwie „build.gradle”. Należy edytować go w sekcji:
dependencies {}
dodając następujący wpis:
implementation 'io.reactivex. rxjava3:rxjava:3.0.12”
Ten wpis to sama biblioteka. W środowisku Android należy dodać drugi wpis
implementation 'io.reactivex. rxjava3:rxandroid:3.0.0”
W momencie pisania tej książki najnowszą wersją była ta oznaczona numerem 3.0.12. Aby sprawdzić jaka jest najnowsza wersja w momencie jej czytania można wejść na stronę:
https://github.com/ReactiveX/RxJava
oraz dla Androida
https://github.com/ReactiveX/RxAndroid
Ponadto RxJava 3 wymaga minimum Javy w wersji 8+, a dla Android poziomu API 21+.
Teraz możemy pobrać biblioteki klikając w Eclipsie na nazwę projektu prawym przyciskiem myszy i wybierając:
Gradle->Refresh Gradle Projekt.
Po tych krokach biblioteka RxJava 3 jest gotowa do pracy.
2. Jak testować RxJava 3?
Istotą reaktywnego programowanie w RxJava 3 jest zarządzanie przesyłem danych między dwoma elementami: obiektem obserwowalnym i przynajmniej jednym obserwatorem. Obserwator rejestruje się w obiekcie obserwowalnym. Następnie obiekt obserwowalny rozsyła określone dane do wszystkich zarejestrowanych obserwatorów. Zatem najpierw należy zapewnić źródło danych:
String[] data = {„a”, „b”, „c”, „d”, „e”, „f”, „g”, „h”, „i”};
Następnie tworzymy obiekt obserwowalny:
Observable<String> observable = Observable.fromArray(data);
Na końcu należy zarejestrować obiekt, który obsłuży poszczególne przekazane elementy danych. Będzie to znana metoda print(), która wyświetli wszystkie elementy.
observable.subscribe(System. out::print);
Całość klasy testowej będzie wyglądać tak:
import io.reactivex.rxjava3.core.*;
public class HelloWorld {
public static void main(String[] args){
String[] data = {„a”, „b”, „c”, „d”, „e”, „f”, „g”, „h”, „i”};
Observable<String> observable = Observable.fromArray(data);
observable.subscribe(System. out::print);
}
}
Po wywołaniu programu powinniśmy zobaczyć ciąg liter:
abcdefghi.
3. Jakie są podstawowe kroki żeby zacząć pracę z RxJava 3?
Aby poprawnie zaimplementować RxJava 3 należy wykonać następujące kroki:
— Identyfikacja strumienia danych.
— Utworzenie obiektu obserwowalnego, który owija strumień danych.
— Wywołanie operatorów z poziomu obiektu klasy Observables (jeżeli w ogóle).
— Rejestracja obserwatorów.
4. Jak przebiega podstawowy tok pracy z RxJava 3?
Podstawą pracy z RxJava 3 jest źródło danych. To ono determinuje rodzaj klasy obserwowalnej:
List<Integer> data = new ArrayList<>(Arrays.asList(0,1, 2, 3, 4, 5, 6, 7, 8,9));
Najlepiej jest skorzystać z obiektu klasy Observable, bowiem służy on do przetwarzania wieloelementowych strumieni danych, których pobranie nie będzie w żaden sposób opóźnione, co najpewniej będzie miało miejsce w przypadku tablicy dostępnej z poziomu kodu:
Observable<Integer> observable = Observable.fromIterable(data);
Gdyby jednak tablica miała pojemność liczoną w tysiącach elementów, które miałyby być pobrane za pomocą sieci dopuszczającej opóźnienia, bardziej odpowiednim byłaby klasa Flowable, która implementuje technikę ciśnienia zwrotnego (backpressure) buforującą dane, które są odbierane nierównomiernie:
Flowable<Integer> flowable = Flowable.fromIterable(data);
Mając już strumień danych i obsługujący je obiekt obserwowalny można zdecydować, w jaki sposób dane ze strumienia mają zostać przetworzone za pomocą operatorów przed przekazaniem ich do odbiorców. W naszym przykładzie użyjemy operatora filter(), który dopuszcza elementy ze strumienia spełniające określony warunek tj. liczby parzyste:
Flowable<Integer> filteredFlowable = flowable.filter(i -> (i % 2 == 0));
Na końcu pozostaje subskrybować obserwatora, który otrzyma poszczególne elementy ze strumienia danych. Tak jak w poprzednim przykładzie będzie to znana metoda print(), która wyświetli wszystkie elementy:
observable.subscribe(System. out::print);
oraz dodatkowy odbiorca dla obiektu klasy Flowable:
filteredFlowable.subscribe(new DisposableSubscriber<Integer>(){
@Override
public void onNext(Integer t){System.out.print(t);}
@Override
public void onError(Throwable t){ }
@Override
public void onComplete(){ }
} );
Całość klasy testowej będzie wyglądać tak:
import io.reactivex.rxjava3.core.*;
import io.reactivex.rxjava3.subscribers. DisposableSubscriber;
public class HelloWorld{
public static void main(String[] args){
List<Integer> data = new ArrayList<>(Arrays.asList(0,1, 2, 3, 4, 5, 6, 7, 8,9));
Observable<Integer> observable = Observable.fromIterable(data);
Flowable<Integer> flowable = Flowable.fromIterable(data);
Flowable<Integer> filteredFlowable = flowable.filter(i -> (i % 2 == 0));
filteredFlowable.subscribe(System. out::print);
filteredFlowable.subscribe(new DisposableSubscriber<Integer>(){
@Override
public void onNext(Integer t){System.out.print(t);}
@Override
public void onError(Throwable t){ }
@Override
public void onComplete(){ }
} );
}
}
Rozdział III. Klasy obserwowalne — Observables
1. Czym są klasy Observables?
Klasy obserwowalne (Observables) to ogólne określenie grupy klas, które są źródłem emisji elementów dla obserwatorów. Aby obserwatorzy nasłuchiwali, muszą zarejestrować się w obiektach obserwowalnych. Klasy obserwowalne obejmują pięć klas. Wybór klasy, która ma obsługiwać określony strumień zależy od właściwości danego strumienia. Wybór ten determinuje również rodzaj obserwatora, który może zarejestrować się w obiekcie obserwowalnym.
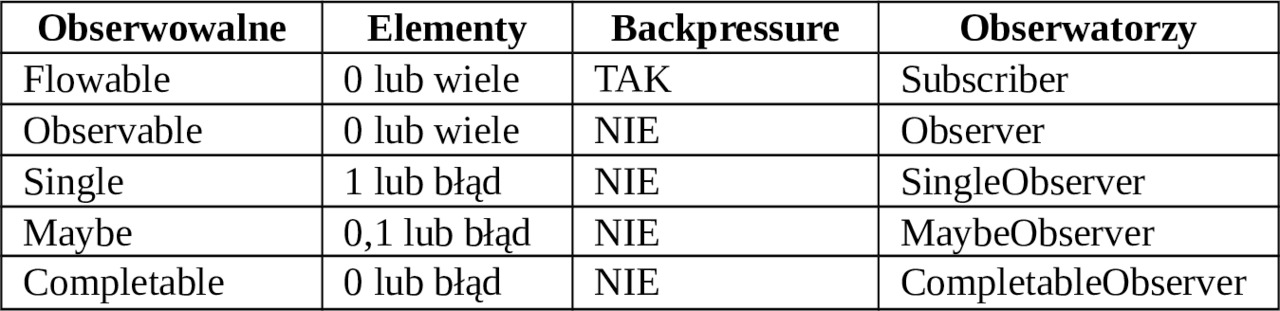
2. Jakie są rodzaje klas Observables?
Zbiór klas obserwowalnych obejmują pięć klas:
— Flowable.
— Observable.
— Single.
— Maybe.
— Completable.
Wybór klasy zależny jest od dwóch głównym czynników: ilości elementów w strumieniu danych i konieczności zastosowania mechanizmu ciśnienia zwrotnego (backpressure). Wybór konkretnej klasy powoduje też konieczność wyboru związanej z nią klasy obserwatora. Wszystkie zależności i kryteria zastosowania klas obserwowalnych pokazuje poniższa tabela:
3. W jaki sposób tworzy się instancję klas obserwowalnych?
Obiekty obserwowalne tworzy się na wiele sposobów. Jednym z nich jest użycie klasy ObservableCreate. Przyjmuje ona w konstruktorze implementację interfejsu ObservableOnSubscribe, który musi obsłużyć metodę subscribe():
Observable<Integer> observable = new ObservableCreate<Integer>(new ObservableOnSubscribe<Integer>(){
@Override
public void subscribe(ObservableEmitter<Integer> emitter) throws Exception {
emitter. onNext(1);
emitter. onNext(2);
emitter. onComplete();
}
});
Możliwe jest także użycie statycznych metod z klasy Observable. Popularna jest metoda create():
Observable<Integer> observable = Observable.create(new ObservableOnSubscribe<Integer>(){
@Override
public void subscribe(ObservableEmitter<Integer> emitter) throws Exception {
emitter. onNext(1);
emitter. onNext(2);
emitter. onComplete();
}
});
Metoda create() może być wywołana przez każdą z klas obserwowalnych. Inna metoda to just(), która wykorzystuje już istniejące dane, aby emitować je do konsumentów:
String data = „Hello world!”;
Observable<String> observable = Observable. just(data);
observable.subscribe(System. out::print);
Aby utworzyć strumień z listy można wykorzystać zestaw metod from():
List<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8));
Observable<Integer> observable = Observable.fromIterable(list);
observable.subscribe(System. out::print);
W ten sposób można także utworzyć instancję z tablicy:
Integer[] array = new Integer[10];
for (int i = 0; i < array. length; i++){
array[i] = i;
}
Observable<Integer> observable = Observable.fromArray(array);
z obiektów Callable:
Callable<String> callable = new Callable(){
@Override
public Object call() throws Exception {
System.out.println(„Hello World!”);
return „Hello World!”;
}
};
Observable<String> observable = Observable.fromCallable(callable);
z obiektów Action:
Action action=()->System.out.println(„Hello World!”);
Observable completable = Observable.fromAction(action);
z obiektów Runnable:
Runnable runnable = () -> System.out.println(„Hello World!”);
Completable completable = Completable.fromRunnable(runnable);
z obiektów Future:
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
Future<String> future = executor.schedule(() -> „Hello world!”, 1, TimeUnit.SECONDS);
Observable<String> observable = Observable.fromFuture(future);
Obiekty obserwowalne można tworzyć też poprzez metodę generate():
int startValue = 1;
int incrementValue = 1;
Flowable<Integer> flowable = Flowable.generate(() -> startValue, (s, emitter) -> {
int nextValue = s + incrementValue;
emitter. onNext(nextValue);
return nextValue;
});
Można użyć klasy Observables do generowania danych za pomocą metody range(), która tworzy sekwencję wartości dla każdego konsumenta:
String data = „Hello World!”;
Observable<Integer> indexes = Observable. range(0, data. length());
Observable<Character> characters = indexes
.map(index -> data.charAt(index));
Inną metodą, która generuje dane jest interval(), która okresowo tworzy wzrastające liczby:
Observable<Long> clock = Observable.interval(1, TimeUnit.SECONDS);
clock.subscribe(time -> {
if (time % 2 == 0){
System.out.println(„Tick”);
} else {
System.out.println(„Tock”);
}
});
Podobne zastosowanie ma metoda timer(), która wykonuje operację po upływie określonego czasu:
Observable<Long> triggerTimer = Observable. timer(5, TimeUnit. MINUTES);
triggerTimer. blockingSubscribe(v -> System.out.println(„It is ready!”));
Do testowania działania obserwowalnych można skorzystać z metod error(), never() lub empty().
4. Jakie jest zadanie klasy ObservableOnSubscribe?
ObservableOnSubscribe to klasa abstrakcyjna z jedną tylko metodą subscribe() przyjmującą za parametr obiekt klasy ObservableEmitter, który jest abstrakcją klasy Observer z dodanymi metodami, bowiem również służy jako źródło danych. W momencie rejestracji obserwatora w klasie Observable zostaje wywołana metoda subscribe() oraz kod emitera:
Observable<Integer> observable = Observable.create(new ObservableOnSubscribe<Integer>(){
@Override
public void subscribe(ObservableEmitter<Integer> emitter) throws Exception {
emitter. onNext(1);
emitter. onNext(2);
emitter. onComplete();
}
});
5. Jak działa klasa Observable?
Klasa Observable jest abstrakcyjną klasą obserwowalną implementującą interfejs ObservableSource. Nie obsługuje mechanizmu zwrotnego ciśnienia (backpressure). Oferuje zestaw standardowych dla klas obserwowalnych operatorów i zdolność do konsumpcji synchronicznych i asynchronicznych strumieni. Operatory z klasy obserwowalnej domyślnie posługują się buforem w rozmiarze 128 elementów, choć większość z nich pozwala na zmianę tego parametru. Tworzenie instancji klasy obserwowalnej możliwe jest za pomocą klasy ObservableCreate lub jednej ze statycznych metod, przeważnie wariantu from() lub create().
Istnieją dwa tryby, w których może działać instancja klasy Observable: blokujący i nieblokujący. W trybie blokującym wszystkie pobrania wartości przez obserwatorów za pomocą metody onNext() są synchroniczne i nie ma możliwości wyrejestrowania obserwatora w czasie zdarzenia. Inaczej nieblokujące, które działają asynchronicznie. Domyślnym trybem pracy jest tryb nieblokujący.
6. Jak działa klasa Flowable?
Klasa Flowable jest abstrakcyjną klasą z pakietu klas obserwowalnych implementującą interfejs Publisher. W przeciwieństwie do klasy Observable obsługuje mechanizm zwrotnego ciśnienia (backpressure). Oferuje zestaw standardowych dla klas obserwowalnych operatorów i zdolność do konsumpcji synchronicznych i asynchronicznych strumieni. Operatory z klasy Flowable domyślnie posługują się buforem w rozmiarze 128 elementów, choć większość z nich pozwala na zmianę tego parametru.
7. Jak działa klasa Single?
Klasa Single jest abstrakcyjną klasą z pakietu klas obserwowalnych implementującą interfejs SingleSource. Jest zadaniem jest przetworzenie odpowiedzi mającej postać jednej wartości. Klasa Single zachowuje się podobnie jak klasa Observable z tym, że może emitować tylko pojedynczą pomyślą wartość lub błąd. Nigdy nie ma miejsca zdarzenie onComplete. Z kolei zdarzenia onSuccess i onError tutaj wzajemnie wykluczające się — inaczej niż w klasie Observable.
8. Jak działa klasa Maybe?
Klasa Maybe jest abstrakcyjną klasą z pakietu klas obserwowalnych implementującą interfejs MaybeSource. Reprezentuje opóźnioną kalkulację i emisję pojedynczych wartości, braku wartości lub wyjątku. Zdarzenia onSuccess, onError i onComplete wykluczają się.
9. Jak działa klasa Completable?
Klasa Completable jest abstrakcyjną klasą z pakietu klas emisję implementującą interfejs CompletableSource. Reprezentuje opóźnioną kalkulację bez zwrotu wartości, zdarzenie onComplete lub wyjątek.
10. Jaki jest cykl życia klas Observables?
Cykl życia ma trzy etapy:
— czas budowania (assembly time).
— czas subskrypcji (subscription time).
— czas działania (runtime).
Czas budowania to okres przygotowania przepływu danych poprzez zastosowanie różnych operatów:
Flowable<Integer> flow = Flowable. range(1, 5)
.map(v -> v * v)
.filter(v -> v % 3 == 0);
Czas subskrypcji to tymczasowy stan, gdy zostaje wywołana metoda subscribe() wobec strumienia, który ustala wewnętrznie łańcuch zdarzeń. W tym momencie wywołaniu podlegają efekty uboczne subskrypcji. Niektóre źródła zaczynają blokować lub emitować element:
flow.subscribe(System. out::println)
Cykl kończy moment, gdy elementy zaczynają być aktywnie emitowane :
Observable.create(emitter -> {
while (!emitter.isDisposed()){
long time = System.currentTimeMillis();
emitter. onNext(time);
if (time % 2!= 0){
emitter. onError(new IllegalStateException(„Odd millisecond!”));
break;
}
}
})
.subscribe(System. out::println, Throwable::printStackTrace);
11. Jak znaczenie mają klasy Schedulers?
Operatory RxJava 3 nie współpracują bezpośrednio z wątkami i egzekutorami, ale działają poprzez harmonogramy w postaci klas Schedulers, które stanowią abstrakcyjną formę zarządzania współbieżnością. RxJava 3 dostarcza kilku standardowych harmonogramów poprzez klasę Schedulers:
— Schedulers.computation() — przeprowadza kosztowne obliczenia na określonej liczbie dedykowanych wątków w tle. Większość asymetrycznych operatorów wykorzystuje ten harmonogram jako domyślny.
— Schedulers.io() — przeprowadza operacje na dynamicznie zmieniającej się liczbie wątków.
— Schedulers.single() — przeprowadza operacje na jednym wątku w sekwencyjny sposób oparty o zasadę FIFO.
— Schedulers.trampoline() — przeprowadza operacje w sekwencyjny sposób oparty o zasadę FIFO w jednym z uczestniczących wątków, przeważnie dla celów testowych.
Powyższe harmonogramy są dostępne dla każdej platformy opartej o JVM. Niektóre platformy mają własne harmonogramy jak: AndroidSchedulers.mainThread(), SwingScheduler.instance() lub JavaFXSchedulers.gui().
Ponadto istnieje możliwość opakowania istniejącej klasy Executor w klasę Scheduler poprzez metodę Schedulers.from(Executor). Można to wykorzystać do posiadania większej, ale stałej puli wątków.
Harmonogramy są instalowane w obiektach obserwowalnych za pomocą dwóch metod: subscribeOn() i observeOn(). Metoda subscribeOn() określa harmonogram (wątek), w którym obiekt obserwowalny będzie działał. Z kolej observeOn() określa harmonogram (wątek), w którym obserwatory będą obserwowały klasę obserwowalną. Można to uprościć do stwierdzenia, że subscribeOn() wskazuje na harmonogram zarządzający kosztownymi obliczeniami, a observeOn() na harmonogram, który będzie zarządzał prezentacją wyników. Dlatego subscribeOn() łączy się głównie z działaniami w tle, a observeOn() z działaniami w głównym wątku, przeważnie na rzecz UI.
12. W jaki sposób łączone są metody tworzące obiekt obserwowalny?
Metody przy tworzeniu obiektu obserwowalnego łączone są łańcuszkowo za pomocą tak zwanego fluent API, które przypomina wzorzec builder. Jednakże typy reaktywne z RxJava 3 pozostają niezmienne, co oznacza, że za każdym wywołaniem metody tworzony jest nowy obiekt obserwowalny. Dla przykładu następujący kod:
Flowable.fromCallable(() -> {
Thread.sleep(1000);
return „Done”;
})
.subscribeOn(Schedulers.io())
.observeOn(Schedulers.single())
.subscribe(System. out::println);
jest równoważny takiemu:
Flowable<String> source = Flowable.fromCallable(() -> {
Thread.sleep(1000);
return „Ok”;
});
Flowable<String> runBackground = source.subscribeOn(Schedulers.io());
Flowable<String> showForeground = runBackground.observeOn(Schedulers.single());
showForeground.subscribe(System. out::println, Throwable::printStackTrace);
13. W jakiej kolejności przebiegają etapy przetwarzania danych ze strumienia?
Co do zasady poszczególne etapy przetwarzania danych przebiegają sekwencyjnie, co oznacza, że najpierw odbywają się obliczenia, a potem przekazywane są ich wyniki w tym samym wątku:
Flowable. range(1, 10)
.observeOn(Schedulers.computation())
.map(v -> v * v)
.blockingSubscribe(System. out::println);
Istnieje także możliwość przeprowadzenia obliczeń równolegle i połączenia wyników w jednym wątku:
Flowable. range(1, 10)
.parallel()
.runOn(Schedulers.computation())
.map(v -> v * v)
.sequential()
.blockingSubscribe(System. out::println);
14. Czy można utworzyć podrzędne strumienie?
RxJava 3 umożliwia tworzenie podrzędnych strumieni. Podrzędne i zależne strumienie można tworzyć za pomocą metody flatMap():
Flowable. range(1, 10)
.flatMap(v ->
Flowable. just(v)
.subscribeOn(Schedulers.computation())
.map(w -> w * w)
)
.blockingSubscribe(System. out::println);
15. Czym są kontynuacje?
Kontynuacje to konstrukcje RxJava 3, w których w momencie gdy element jest dostępny zaistnieje potrzeba wykonania na nim określonych kalkulacji. Kontynuacja może być zależna, gdy wobec określonego elementu wywołuje się usługę, czeka, a następnie kontynuuje z jej wynikiem:
service. apiCall()
.flatMap(value -> service.anotherApiCall(value))
.flatMap(next -> service.finalCall(next))
Możliwe jest także wykorzystanie elementu z poprzedniego mapowania:
service. apiCall()
.flatMap(value ->
service.anotherApiCall(value)
.flatMap(next -> service.finalCallBoth(value, next))
)
Kontynuacja może też być niezależna, w sytuacji gdy wynik z obliczeń nie ma znaczenia dla reszty obliczeń:
Observable continued = sourceObservable. flatMapSingle(ignored -> someSingleSource)
continued.map(v -> v.toString())
.subscribe(System. out::println);
Występują też zależne opóźnione kontynuacje, w sytuacji gdy istnieje pośrednia zależność między sekwencjami, która z pewnych względów nie została uwzględniona w zwykłych kanałach.
AtomicInteger count = new AtomicInteger();
Observable. range(1, 10)
.doOnNext(ignored -> count.incrementAndGet())
.ignoreElements()
.andThen(Single.defer(() -> Single.just(count.get())))
.subscribe(System. out::println);
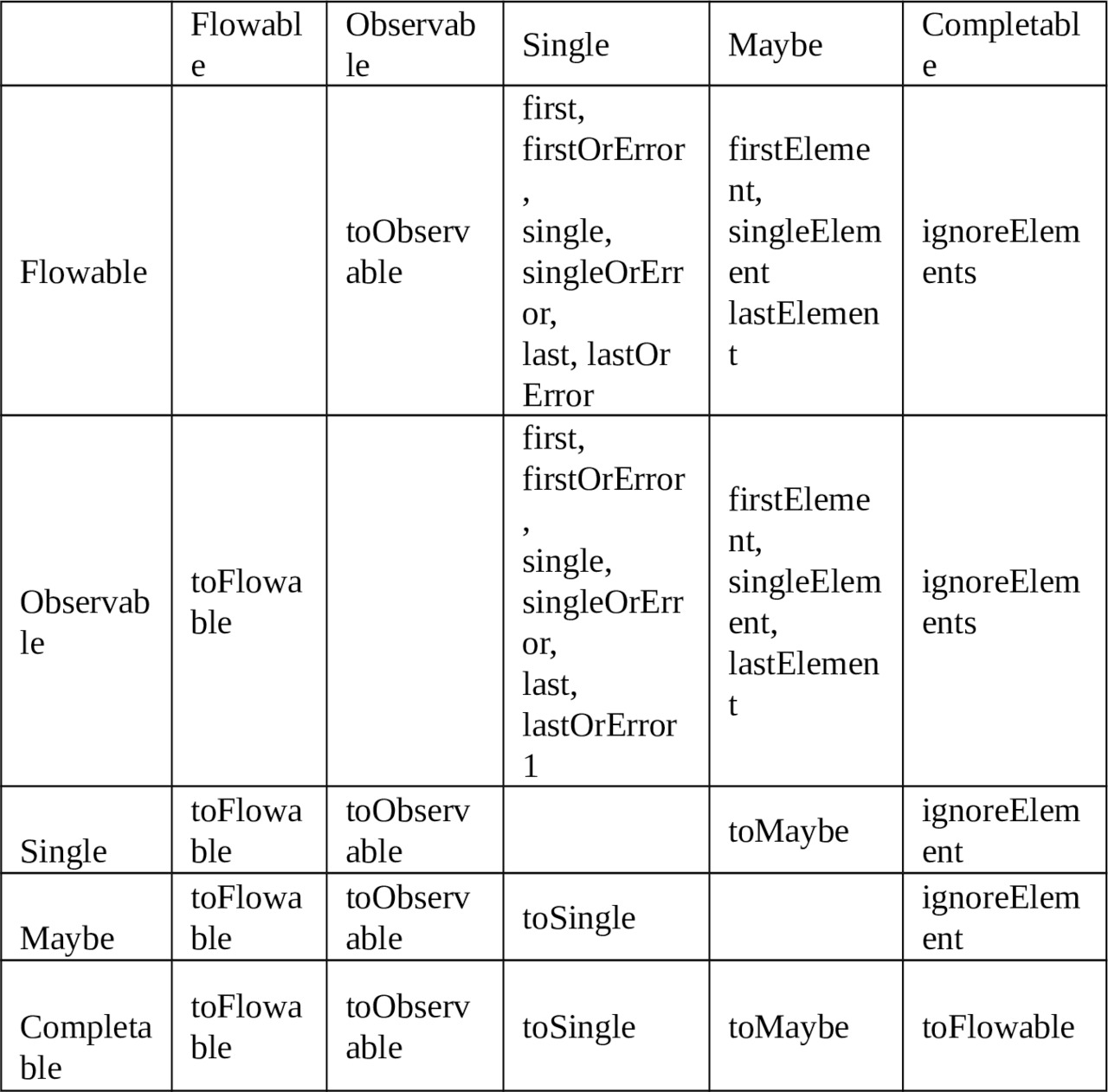
16. Czy można konwertować typy Observables?
Czasami usługa zwraca inny rodzaj obiektu obserwowalnego niż ten, z którym chcemy pracować. Aby uzyskać potrzebny typ obserwowalny możemy zastosować jedno z dwóch rozwiązań:
— Przekonwertowanie do żądanego typu.
— Znalezienie i użycie przeciążonego operatora wspierającego dany typ.
Konwersja do żądanego typu dokonywana jest za pomocą operatorów, w które wyposażona jest każda z klas obserwowalnych. Poniższa tabela przestawia możliwe kombinacje. Pierwsza kolumna przedstawia typ podstawowy, a pierwszy wiersz typ docelowy.
Drugi sposób polega na znalezieniu i użyciu przeciążonego operatora wspierającego dany typ. Wiele z popularnych operatorów ma swoje przeciążone odpowiedniki, które współpracują z różnymi typami:
Kup książkę, aby przeczytać do końca.