
Bezpłatny fragment - Eksploracja danych na przykładzie wybranej gry losowej
Wstęp
Data mining jako interdyscyplinarna część informatyki, w znanej obecnie formie, istnieje od niedawna. Wraz z rozwojem gospodarki i ogólnie pojętej nauki w sposób znaczący zwiększyła się ilość danych. Nasiliła się także świadomość z możliwych korzyści wykorzystania zebranych danych. Naprzeciw tym korzyściom wychodzi informatyka, dając stosowne narzędzia umożliwiające odpowiednie, sprzyjające występującym potrzebom, przetwarzanie danych. Aktualnie istnieją już pewne metody eksploracji danych, jednak ogrom zastosowań tej dziedziny w wielu obszarach działalności człowieka sprawia, że możliwości rozwoju data mining jeszcze się nie wyczerpały.
Eksploracja danych stanowi niezwykle istotną i bardzo dynamicznie rozwijającą się dziedzinę. Korzysta z narzędzi informatycznych, w tym także ze sztucznej inteligencji, ale także z możliwości, jakie niesie ze sobą statystyka. Intensywny postęp wymaga tworzenia takich rozwiązań informatycznych, które będą mogły być wykorzystane do efektywnej analizy wciąż poszerzających się zbiorów danych.
Do podjęcia tematu przyczynił się fakt, że data mining, w istniejącej postaci ma dość krótką historię. Daje to szansę na przedstawienie tematu w niewystępującym dotychczas aspekcie, dzięki czemu zagadnienia, zwłaszcza te dotyczące części badawczej, nie będą powielane po innych autorach — analiza wyników gry losowej Lotto w odniesieniu do omawianego problemu nie jest popularna. W pracy poruszone zostały zagadnienia związane właśnie z eksploracją danych — omówione są pojęcia odnoszące się do tego tematu, co stanowi wprowadzenie do zagadnienia. W ramach pracy zrealizowano projekt i implementację własnych aplikacji, których zadaniem jest wsparcie analizy wyników losowej gry Lotto. Praca łączy w sobie aspekt analityczny, zagadnienia programistyczne, czyli zagadnienia zgodne z zainteresowaniami autorki pracy, które jednocześnie są związane z realizowaną na studiach specjalnością. Należy podkreślić, że efekty pracy niosą ze sobą wymierne korzyści dla współczesnej nauki — otrzymane wyniki dają profity zarówno dla statystyków — wskazują możliwy do zastosowania obszar, jak i dla programistów — pokazują bowiem możliwości wykorzystanych języków programowania wraz z współistniejącymi technologiami w analizowanym obszarze.
Zasadniczym celem pracy było wykazanie użyteczności języków Java oraz C# w analizie wyników gry Lotto. Celem pomocniczym było porównanie i ocena uzyskanych wyników. Na podstawie założonego celu, przyjęło się następującą tezę: język Java oraz język C# są przydatne do wykonania analizy statystycznej wyników gry losowej Lotto. Z tak postawionej tezy wynikły pytania badawcze:
— jakie są możliwości języka Java w analizie statystycznej wyników wybranej gry losowej?
— jakie są możliwości języka C# w analizie statystycznej wyników wybranej gry losowej?
— jaka jest różnica przedstawionych analiz?
Ze względu na bardzo duży zakres podłoża teoretycznego związany z omawianym zagadnieniem, w pracy ograniczono się do przedstawienia podstawowych pojęć nawiązujących do eksploracji danych. Szczegółowa i dogłębna analiza literatury przedmiotu znacznie rozszerzyłaby objętość pracy i nie zawsze odnosiłaby się ściśle do jej przeznaczenia. Ograniczenie występuje także w nawiązaniu do części praktycznej. Istnieje bowiem wiele rozwiązań informatycznych, które mogą być zastosowane w odniesieniu do data mining. Zastosowanie ich wszystkich lub chociażby części z nich miałoby znaczny wpływ na zwiększenie rozmiar niniejszego opracowania, jak również istotnie wpłynęłaby na czas jej realizacji. Jednocześnie nie zawsze przyniosłoby to wymierne rezultaty.
Aby udowodnić powyżej sformułowaną tezę, w pierwszej kolejności wykonuje się analizę literatury dotyczącej eksploracji danych, także w odniesieniu do baz danych, co jest przedstawione w rozdziale 1. W szczególności wykorzystana jest tutaj publikacja Marcina Szeligi, w której autor omawia najważniejsze aspekty data mining i uczenia maszynowego.
Kolejnym krokiem jest stworzenie dwóch aplikacji. Jedna z nich napisana jest w języku C#, natomiast druga w języku Java. Zadaniem obu aplikacji jest analiza losowań gry Lotto. Zatem rozdział drugi i trzeci przeznaczone są na analizę oraz prezentację tychże aplikacji komputerowych. Rozdział czwarty stanowi porównanie obu aplikacji. Natomiast rozdział 5 to porównanie osiągniętych wyników. Zasadnicza część pracy kończy się podsumowaniem, w którym dokonuje się odniesienia do przedstawionej tezy.
Rozdział 1. Wprowadzenie do problematyki eksploracji danych
Eksploracja danych
Definicja
Eksploracja danych (ang. data mining, określana również jako drążenie danych, wydobywanie, danych czy też ekstrakcja danych) jest pojęciem stosowanym na gruncie wielu nauk i dziedzin życia człowieka, min w medycynie, zarządzaniu oraz informatyki. Oznacza wydobywanie wiedzy z istniejących baz danych i stanowi jeden z kilku etapów procesu uzyskiwania wiedzy ze zbiorów danych. Ideą data mining jest głównie wykorzystanie prędkości komputerów do znajdowania ukrytych dla człowieka (ze względu na możliwości czasowe) prawidłowości występujących w danych zgromadzonych w hurtowniach danych.
W dostępnej literaturze występuje dużo prób wyjaśnienia, czym jest eksploracja danych. Definicje te różnią się od siebie ze względu na różne podejście środowisk naukowych i biznesowych do eksploracji danych. „Eksploracja danych jest dziedziną informatyki, która integruje szereg dyscyplin badawczych takich jak: systemy baz danych i hurtowni danych, statystyka, sztuczna inteligencja, uczenie maszynowe i odkrywanie wiedzy, obliczenia równoległe, optymalizacja i wizualizacja obliczeń, teoria informacji, systemy reputacyjne”.
Inna definicja mówi, że „data mining nazywana eksploracją danych, lub odkrywaniem wiedzy w bazach danych, to proces odkrywania reguł, wzorców i zależności”. Mówi się również, że eksploracja danych to „kompletna metodologia CRISP-DM (ang. Cross-industry standard proces for data mining) opracowana przez trzy przedsiębiorstwa przemysłowe: SPSS (ang. Statistical package for the social science), NCR (ang. National cash register corppration) oraz Daimler Chrysler. Metodologia ta dostarcza ujednolicony, elastyczny oraz kompletny model przeprowadzania procesu eksploracji danych w przedsiębiorstwach, niezależnie od ich specyfikacji”.
Schemat metodyki CRISP-DM został przedstawiony poniżej.
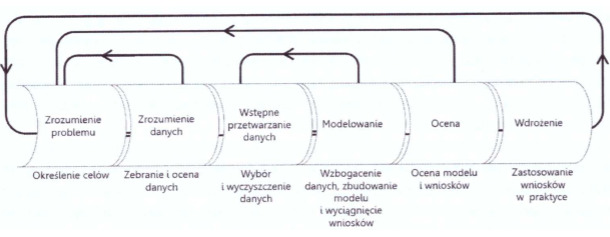
Rysunek 1. Metodyka CRISP-DM
Źródło: Szeliga M. Data science i uczenie maszynowe, Wydawnictwo Naukowe PWN, Warszawa 2017, s. 3.
Metodyka CRISP-DM zwraca uwagę na iteracyjny i zwinny charakter procesu wydobywania wiedzy z danych. Wyniki otrzymywane na każdym etapie są oceniane, a na tej podstawie podejmowana jest decyzja o ewentualnym powtórzeniu któregoś z wcześniej wykonanych kroków.
Wykorzystując dostępne technologie, data mining wspiera inne dyscypliny naukowe oraz przemysł. Jako dziedzina interdyscyplinarna, eksploracja danych łączy w sobie techniki uczenia maszynowego, rozpoznawania wzorców, metody statystyczne, wizualizację oraz sztuczną inteligencję. Jej zadaniem jest pozyskiwanie informacji z dużych repozytoriów danych. „Celem eksploracji danych jest wykorzystanie właściwego algorytmu dla znajdowania zależności i schematów w przygotowanym zbiorze danych, a następnie ich reprezentacja w postaci formalnej, zrozumiałej dla użytkownika”.
Interdyscyplinarność eksploracji danych polega również na połączeniu ze sobą matematyki, statystyki, algorytmów data science, wiedzy dziedzinowej czy też informatyki — m.in. programowanie, bazy danych, big data, bezpieczeństwo.
Od ostatniej dekady XX wieku eksploracja danych uważana była za etap procesu odkrywania wiedzy (knowledge discovery). W dostępnej literaturze pojęcia takie jak eksploracja danych (data mining), odkrywanie wiedzy w bazach (Knowledge Discovery in Databases) oraz eksploracja baz danych (Database Mining) są stosowane zamiennie. Odkrywanie wiedzy z baz danych opiera się wyszukiwaniu czytelnych schematów i wzorców, które wcześniej nie były znane, a które potencjalnie mogą być użyteczne dla wspomagania decyzji oraz dokonywania charakterystyki baz danych. Omawiany proces korzysta z wielu doświadczeń oraz metod z takich dziedzin jak sztuczna inteligencja oraz uczenie maszynowe. Dodatkowym problemem może być to, że proces odkrywania wiedzy może być problemowy ze względu na olbrzymią ilość danych, na których należy operować oraz fakt, że z tymi danymi współbieżnie pracuje wiele użytkowników.
Eksploracja danych może być również określana mianem uczenia maszynowego, stosowanego do sytuacji i zdarzeń, które nie mogą być opisane w sposób algorytmiczny lub ich opis byłby wysoce skomplikowany czy też nieskuteczny w praktyce, np. próba opisu sytuacji, w których dochodzi do oszustw dokonywanych za pośrednictwem kart płatniczych. Odpowiedzią na takie sytuacje jest uczenie maszynowe. Polega ono na tym, że zastępuje pisanie programów komputerowych, których zadaniem byłaby realizacja poszczególnych zadań. W to miejsce gromadzone są dane opisujące spodziewane wyniki oraz używa się ich jako dane treningowe odpowiedniego algorytmu maszynowego. Model, który powstaje w taki sposób ma za zadanie odpowiadać na pytania predykcyjne.
Uczenie maszynowe, w literaturze znane również pod nazwą Machine Learning, stanowi analizę procesów uczenia się, jak również tworzeniem systemów doskonalących swoje działanie w oparciu o doświadczenia z przeszłości. Stanowi część sztucznej inteligencji czy też inteligencji obliczeniowej.
Wyraźnie jest widoczne, że centralnym elementem tego procesu są dane, które zostają poddane kolejnym przekształceniom i modelowaniu, czego celem jest wydobycie ukrytych informacji z tych danych. Proces ten od czasu jego początków aż do dnia dzisiejszego ulegał zmianom.
W literaturze, proces eksploracji danych występuje pod innymi nazwami: pozyskiwanie danych, ekstrakcja danych, data mining, zgłębianie danych. Mówi się, że „jest to proces analityczny, przeznaczony do badania dużych zasobów danych (zazwyczaj powiązanych z zagadnieniami gospodarczymi lub rynkowymi) w poszukiwaniu wzorców oraz systematycznych współzależności pomiędzy zmiennymi, a następnie do oceny wyników poprzez zastosowanie wykrytych wzorców oraz systematycznych współzależności pomiędzy zmiennymi, a następnie do oceny wyników poprzez wykorzystanie otrzymanych modeli do nowych podzbiorów danych”.
Każda definicja, niezależnie od przyjmowanego punktu widzenia, ma wspólną podstawę. Jest nią analiza zbiorów danych obserwowanych w celu znalezienia nieoczekiwanych związków i podsumowania danych w sposób oryginalny tak, by wnioski były zarówno zrozumiałe, jak również przydatne w odpowiednich zastosowaniach.
Dokonywana analiza zbiorów danych umożliwia odkrywanie nowych powiązań, zwłaszcza nietrywialnych, które wcześniej nie były znane odbiorcy. Podsumowanie odkrytych zależności w sposób zrozumiały i uporządkowany może dostarczyć osobom zainteresowanym istotnych informacji, a co za tym idzie także wiedzę.
Wsparcie informatyki w zakresie eksploracji danych jest nieocenione. Bowiem ilość danych i informacji we współczesnym świecie rośnie z prędkością wręcz wykładniczą, co coraz bardziej utrudnia ich analizę z wykorzystaniem tradycyjnych systemów bazodanowych. Rozwój technologii informatycznych, a zwłaszcza technologii generowania, przechowywania oraz przetwarzania danych wpływa na ilość danych cyfrowych, których liczba wzrasta rocznie o około 30%. Eksploracja danych pełni ogromną rolę w wydobywaniu tych danych.
Odkrywanie wiedzy stanowi czynność naturalną dla każdego człowieka. Ludzki mózg jest w stanie analizować i rozpoznawać wzorce danych o nawet bardzo skomplikowanym charakterze. Dowodem na to może być zdolność rozpoznawania ludzi po głosie, rysach twarzy czy też innych cechach osobniczych.
Z jednej strony dostępne źródła mówią, że odkrywanie danych i ich eksploracja stanowią pojęcia, które mogą być stosowane zamiennie. Istnieją też jednak publikacje, które rozróżniają te dwa pojęcia twierdząc, że odkrywanie wiedzy odnosi się do całego procesu, a eksploracja danych jest jedynie jednym z jego etapów i odnosi się do generowania reguł. Pozostałe etapy procesu nawiązują do przygotowania danych, ich wyboru do eksploracji, czyszczenia, definiowania dodatkowej wiedzy o charakterze przedmiotowej oraz do interpretacji wyników eksploracji oraz ich wizualizacji.
Data mining jest procesem skomplikowanym, jednak nie jest celem samym w sobie — stanowi bowiem punkt wyjścia do decyzji i dalszych działań. Kroki podjęte w ramach eksploracji danych muszą być wykonane w sposób fachowy i rzetelny. Rzutują one bowiem na skutki dalszych kroków podjętych na uzyskanych wcześniej wynikach.
Eksploracja danych powinna być rozumiana jako składowa całego procesu ich analizy. Na proces ten składa się kilka kroków, przedstawionych na schemacie poniżej.
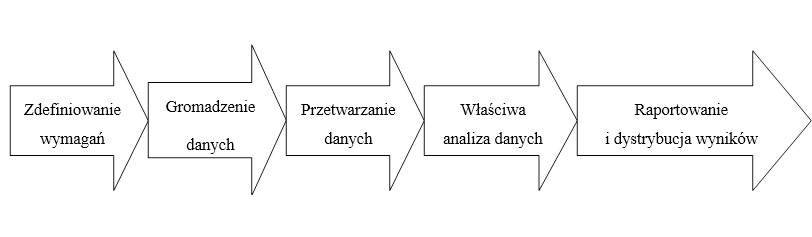
Rysunek 2. Proces analizy danych
Źródło: opracowanie własne na podstawie: https://mfiles.pl/pl/index.php/Analiza_danych, stan na dzień 09.06.2019
Pierwszym krokiem w analizie danych jest zdefiniowanie wymagań. Na tym etapie określane są dokładne wymagania jakościowe wobec zbiorów. W wyborze danych należy kierować się tym, co ma być mierzone oraz w jaki sposób.
Drugim etapem jest gromadzenie danych. Dane są kolekcjonowane z różnych źródeł. Istnieje wiele różnych źródeł pozyskiwania danych, w zależności od sytuacji.
Trzecim krokiem jest przetwarzanie danych. Zebrane dane muszą być przetworzone oraz zorganizowane w sposób logiczny w stosunku do analizy, np. zamieszczone w tabeli. Następnie należy dane oczyścić, jeśli w zebranym zbiorze znajdują się dane powtarzające się, niekompletne, zawierające błędy.
Następnie wykonywana jest właściwa analiza danych. Istnieje wiele możliwych do wykorzystania metod, min. właśnie data mining i badania eksploracyjne. Badania eskploracyjne mogą być wykorzystane do analizy zbiorów w celu wyznaczenia odrębnych cech tych zbiorów, a to z kolei może zostać wykorzystane do przetestowania pierwotnej hipotezy. Do metod analizy należy również statystyka, jak również modelowanie i tworzenie formuł matematycznych. Jest to stosowane w celu identyfikacji zależności występujących pomiędzy zmiennymi, takich jak korelacja czy też przyczynowość.
Raportowanie oraz dystrybucja wyników stanowią ostatni etap procesu analizy danych. Mogą być tu stosowane różne sposoby wizualizacji tak, aby w sposób jasny i skuteczny zaprezentować wnioski z dokonanej analizy. Wizualizacja danych wykorzystuje róże formy graficzne — każda z nich ma swoje wady i zalety w zależności od konkretnej sytuacji.
Etapy odkrywania wiedzy
Proces odkrywania wiedzy składa się z kilku etapów. Usama Fayyad, Gregory Piatetsky — Shapiro i Padhraic Smyth w swoim artykule poświęconym odkrywaniu wiedzy trafnie odwzorowują ten proces za pomocą dobrze skonstruowanego schematu. Został on zaprezentowany poniżej.
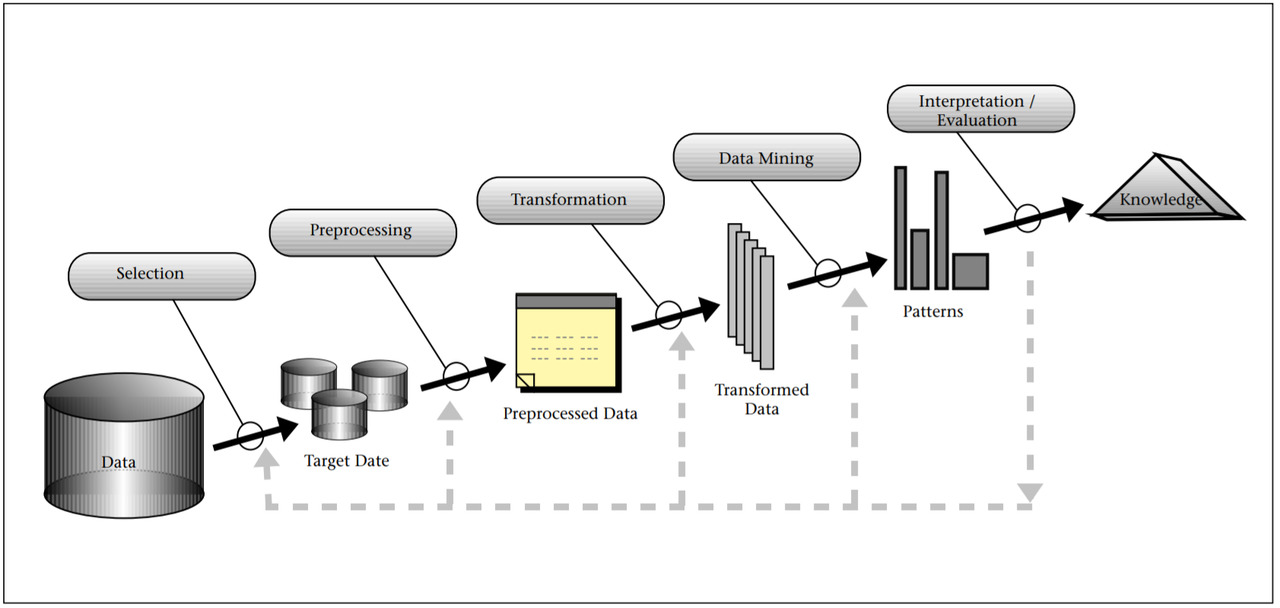
Rysunek 3. Proces odkrywania wiedzy
Źródło: Fayyad U., Piastetsky-Shapiro G., Smyth P., From Data Mining to Knowledge Discovery in Databases, „Al. Magazine” 1996, vol. 17 Number 3, s. 41.
Na każdym etapie procesu zasadniczą rolę odgrywają dane, które na każdym poszczególnym kroku są poddawane kolejnym przekształceniom i modelowaniu, czego celem jest wydobywanie ukrytych w nich informacji. W pierwszej kolejności, z dostępnego zbioru danych dokonuje się ich wyboru, tzw. danych treningowych, które będą poddane dalszemu przetwarzaniu. Kolejnym krokiem jest ich wstępne przetwarzanie, w wyniku czego otrzymuje się przetworzone dane, które na kolejnym etapie mają być wzbogacone. Po tym etapie swoją rolę odgrywa eksploracja. W wyniku działań przeprowadzonych na gruncie eksploracji danych otrzymuje się wzorce, które stanowią podstawę do wykonania wzorców. Wzorce stanowią punkt wyjścia do interpretacji oraz oceny otrzymanych rezultatów i zdobycia informacji wynikającej z przeprowadzonego procesu odkrywania wiedzy.
Geneza
Pojęcie data science pierwszy raz zostało użyte przez Petera Naura w roku 1960 i określało ono wtedy metody automatycznego przetwarzania danych przy użyciu komputerów. Od tamtej pory termin ten jest stosowany w środowisku naukowym. Początkowo był w użyciu wśród statystyków i określał analizy statystyczne wspomagane komputerowo. Statystykami korzystającymi z tej definicji byli C.F. Jeff Wu oraz William S. Cleverland.
Pojawienie się w informatyce takiej dziedziny jaką jest data mining nie powinno dziwić. Ludzkość generuje oraz przetwarza coraz większe ilości danych z różnych dziedzin swojej działalności. Niezależnie od dziedziny, dane są gromadzone w zastraszającym tempie. Zaistniała pilna potrzeba, aby powstawały nowe generacje teorii obliczeniowych oraz narzędzi, których zadaniem byłoby wspieranie człowieka w zdobywaniu potrzebnych informacji z bardzo szybko poszerzających się zbiorów danych cyfrowych. Te teorie i narzędzia są przedmiotem zainteresowania inżynierów związanych z odkrywaniem wiedzy z baz danych.
Duże ilości danych zawierają w sobie atrakcyjne prawidłowości i wzorce, które mogą opisywać na przykład preferencje klientów, pozwalają zauważyć pewne schematy występujące w ich zachowaniach. Poznanie tych wzorców może być kluczem do sukcesów niejednego przedsiębiorstwa. Powstanie data mining stało się technologią dająca narzędzia do poznania tych wzorców. Takie wzorce są potrzebne nie tylko dla komercyjnych przedsiębiorstw. Bowiem może być wykorzystywana również w nauce — chociażby medycynie, farmacji czy innych naukach biologicznochemicznych.
Ilość danych nie jest jedynym czynnikiem wpływającym na rozwój omawianego zagadnienia. Znaczenie ma również rozwój technologii baz danych, hurtowni danych oraz automatycznych narzędzi wykorzystywanych do gromadzenia danych. Systemy informatyczne stały się bardzo powszechne. Wzrasta również świadomość użytkowników systemów z branży informatycznej. Dodatkowo ceny sprzętów komputerowych stają się względnie niskie w stosunku do lat ubiegłych. Ma to oczywiście ścisły związek z ilością gromadzonych danych w różnego typu przedsiębiorstwach, urzędach czy też placówkach badawczych.
Obszary zastosowań
Jak wspomniano już we wcześniejszej części pracy, eksploracja danych ma wiele sektorów, na płaszczyźnie których jest wykorzystywana. Jest istotnym czynnikiem ich rozwoju. Do głównych obszarów zastosowań omawianego zagadnienia należą:
— medycyna, w ramach której eksploracja danych może zwiększyć skuteczność leczenia i zapobiegać chorobom. Zastosowanie data mining w zakresie medycyny może wspierać diagnostykę.
Wiele dostępnych publikacji i raportów przedstawiających wyniki badań medycznych wykorzystują metody statystyczne do analizy danych. Statystyka jest tu wykorzystywana na wielu etapach — od planowania badań, np. od dobory liczności próby, aż po budowę modeli, których zadaniem jest opisanie złożonych zależności. Zauważa się coraz większy nacisk na podejmowanie decyzji opartych o wyniki analiz statystycznych. Wszystkie zmiany standardów leczenia, wykorzystywanie nowych terapii oraz leków muszą być podparte stosowanymi badaniami empirycznymi oraz być potwierdzone wynikami analiz.
W medycynie dane mają szczególne znaczenie, niezależnie czy dotyczą one podstawowej opieki zdrowotnej czy też które są gromadzone w nowoczesnych klinikach i które zawierają kompletne, szczegółowe informacje dotyczące symptomów choroby, wyników testów medycznych, czy też sposobu wyboru i przebiegu zastosowanych terapii. Statystyka oraz data mining mają istotne zastosowanie w medycynie w obszarze projektowania badań, wspomagania decyzji diagnostycznych, stosowania nowej terapii czy leku, podejmowania decyzji w zakresie prewencji i chorób oraz badań prewencyjnych, analizy wyników badań klinicznych, badań genetycznych, metaanalizy, automatyzacji sprawozdawczości czy też text mining.
— biznes, na gruncie którego eksploracja danych znalazła dużo praktycznych zastosowań, a umiejętność wykorzystania narzędzi data mining może zwiększyć zyski oraz doprowadzić do rozwoju przedsiębiorstw.
Zastosowanie data mining w biznesie jest bardzo szerokie. Jak już wspomniano wcześniej, wyniki tego procesu mogą być wykorzystywane do budowania wiedzy w zakresie zachowań konsumenckich oraz ich wyborów. To z kolei ma znaczący wpływ na wybory i decyzje przedsiębiorstw oraz ich rozwój.
Wyniki eksploracji danych na gruncie biznesu mogą pomóc podejmować decyzje biznesowe czy wykryć trendy w sprzedaży artykułów. Mogą być również przydatne w planowaniu kampanii reklamowych czy też przewidzieć lojalność klienta. Zastosowań, jak widać, data mining na gruncie biznesu, jest wiele. Wymienione stanowią jedynie przykłady.
— technika, na przykład do diagnozy skomplikowanej infrastruktury technicznej.
— biotechnologia, gdzie eksploracja danych jest skutecznym narzędziem wspierającym badania w tej dziedzinie.
— inne, czyli wszędzie tam, gdzie występują zbiory danych, których rozmiary sprawiają, że ich analiza może być bardzo trudna lub wręcz niemożliwa do wykonania przez człowieka bez wsparcia dodatkowych narzędzi.
O zastosowaniach data science pisał równie William S. Cleveland. Twierdzi on, że zastosowanie Data Science mieści się w obszarach:
— wykorzystania metod naukowych, procesów, algorytmów oraz systemów do wydobywania wiedzy, jak również spostrzeżeń przyjmujących różne formy — strukturalne oraz nieustrukturyzowane,
— rozwiązywania problemów wykorzystujących matematykę oraz dużych rozmiarów ilościowe środowiska programistyczne wzorowane na matematyce,
— umiejętności radzenia sobie z artefaktami organizacyjnymi na dużą skalę przetwarzania klastrowego,
— umiejętności radzenia sobie ze znaczącymi nowymi ograniczeniami związanymi z algorytmami stwarzanymi przez świat wieloprocesorowy czy też sieciowy.
Data science jako metoda naukowa
Nauki techniczne rozwijają się na podstawie realizacji pewnych konkretnych kroków. Przedstawiono je na schemacie poniżej.

Rysunek 4. Schemat rozwoju nauk ścisłych
Źródło: Szeliga M. Data science i uczenie maszynowe, Wydawnictwo Naukowe PWN, Warszawa 2017, s. 12.
Teoretycznie, badacze, w wyniku obserwacji, formułują hipotezy, które następnie weryfikują na podstawie przeprowadzonych doświadczeń. Aby tego dokonać, posługują się statystyką, która stanowi narzędzie do oceny danych. Następnie, na podstawie wyników wyciągane są stosowne wnioski. Aktualnie, metoda ta jest w fazie kryzysu. Dzieje się tak m.in. dlatego, że istnieją badania, które rozpoczynają się od przyjęcia wniosków za prawdziwe, a następnie dobiera się dane bądź metody do ich analizy tak, aby hipoteza z góry została przyjęta. Innym powodem może być uogólnianie hipotez.
Meta data science wygląda nieco inaczej, co zostało przedstawione poniżej.
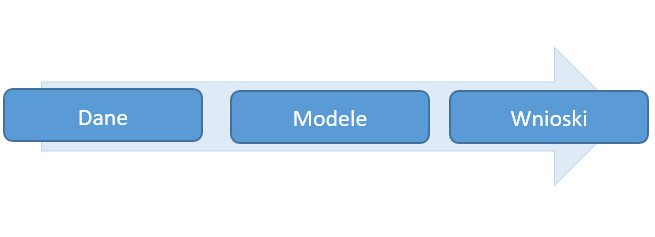
Rysunek 5. Schemat metody data science
Źródło: Szeliga M. Data science i uczenie maszynowe, Wydawnictwo Naukowe PWN, Warszawa 2017, s. 13.
W tej metodzie punktem wyjścia są dane. Wiarygodność wniosków jest zależna od reprezentatywności danych treningowych. Jest to jednak do sprawdzenia poprzez ocenę dokładności oraz wiarygodności modeli przy użyciu danych kontrolnych. Dodatkowo, w metodzie data science wszystkie wnioski, które są wyciągnięte na podstawie wyników modelowania muszą być konsekwencją zrozumienia danych, a co za tym idzie, muszą być także zweryfikowane przez eksperta danej dziedziny.
Uczenie maszynowe jako element eksperymentów data science
Modelowanie
Człowiek ze swej natury jest istotną ciekawą świata, chcącą mieć wpływ na otaczający go świat. Na tej podstawie tworzone są pewne schematy i modele rzeczywistości, co czynione jest w oparciu o ludzką zdolność obserwacji oraz analizy różnego typu zależności występujących między wielorakimi zdarzeniami. Idąc tym tropem, każdy z nas może modelować różne wzorce. Stąd też człowiek ma możliwość dostrzeżenia cyklicznych zajść i zachowań, trendów czy też zdarzeń przyczynowo skutkowych.
Wspomniane już modele tworzone są przez obiekty, które stanowią ich podstawowy składnik. Obiekty te posiadają pewne cechy i właściwości, mogą być przyczyną zdarzeń lub też reagować na nie. W danym modelu, każdy obiekt posiada pewną swoją definicję. Dlatego też pierwszym krokiem w modelowaniu będzie zdefiniowanie obiektów w odniesieniu do dostępnych źródeł.
Kolejny etap modelowania to określenie zdarzeń. Zdarzeniem jest coś, co się już wydarzyło lub wydarzy się z dużym prawdopodobieństwem. Biznesowy model świata zakłada, że świat opiera się na zajściach przyczynowo — skutkowych. Stąd też i zdarzenia zostały przez kogoś lub coś wywołane, a skutkiem tego wpływu jest zmiana stanu modelu. W modelowaniu odnoszącym się do eksploracji danych, tym co najbardziej interesuje analityków, jest ocena skutków zdarzeń.
Ocena zmian przyjmuje względną formę. Nie jest bowiem możliwe, aby opisać cały kontekst wystąpienia danego zdarzenia. Dane źródłowe uwzględnią jedynie częściowy opis obiektów oraz zajść. Wszystkie niezdefiniowane elementy pozostają nieznane aż do momentu, w którym zaprezentowane przez analityka wyniki okażą się banalne lub też pozbawione praktycznego zastosowania. W data science ten problem rozwiązany jest przy pomocy paradygmatu o nazwie download the world. Oznacza to, że istnieje techniczna możliwość, aby przechowywać i przetwarzać dowolnie dużą ilość zbiorów danych, które dają możliwość testowania różnych hipotez.
Trzecim etapem każdego modelu są reguły. W tej części dochodzi do reprezentacji, które występują w ramach schematu regularności zachowania się obiektów. Im dokładniejszy jest opis obiektu oraz im pełniejszy jest opis związanych z nim zdarzeń, tym mocniejszy będzie związek pomiędzy modelowanymi regułami a zależnościami, jakie występują pomiędzy rzeczywistymi obiektami. W celu uzyskania jak najsilniejszego związku, należy skorzystać z paradygmatu download the world.
Model stanowi zbiór reguł, formuł i równań, które wyodrębnione są lub mogą być z danych źródłowych. Model może umożliwić zrozumienie badanego układu oraz przewidzieć jego dalsze zachowania.
Modele stanowią zatem podstawę w eksploracji danych. Dobrze wyodrębnione i opisane będą punktem wyjścia do rzetelnej eksploracji danych, a co za tym idzie, również do tworzenia dobrych wniosków. Oczywiście dobrze skonstruowany model nie jest gwarancją właściwych wniosków, ale błędy na poziomie modeli nie dadzą poprawnych konkluzji.
Wiedza i proces maszynowego uczenia się
Definicja wiedzy może być różna w zależności od dziedziny, na łamach której jest analizowana. W odniesieniu do informatyki, wiedzę można określić jako „ogół wiarygodnych informacji o świecie wraz umiejętnością ich wykorzystania”. Wiedza może być również rozumiana jako umiejętność interpretacji i działania. W odniesieniu do uczenia maszynowego, dobra definicja wiedzy jest podana przez Toma Beckmana, który twierdzi, że wiedza jest wnioskowaniem o informacjach oraz danych ułatwiających działalność, rozwiązywanie problemów, uczenie się i nauczanie.
Tak rozumiana wiedza daje możliwość analizy maszynowego procesu uczenia się w oparciu o modele. Proces uczenia się może odbywać się na podstawie dwóch etapów.
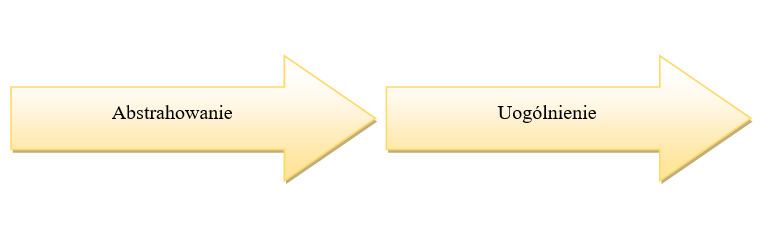
Rysunek 6. Etapy procesu uczenia się
Źródło: Szeliga M. Data science i uczenie maszynowe, Wydawnictwo Naukowe PWN, Warszawa 2017, s. 7.
Abstrahowanie stanowi pierwszy etap przekształcania doświadczeń wynikających z obserwacji w wiedzę. W tym czasie jakościowe opisy zdarzeń są przekształcane w opisy ilościowe.
Drugim etapem procesu uczenia się jest uogólnianie, zwane również generalizacją. Umożliwia to zastosowanie doświadczeń zdobytych w przeszłości do sytuacji obecnych.
Techniki i metody analiz
Techniki i metody eksploracji danych stanowią zasób bardzo istotny dla analizy danych, ponieważ zawiera matematyczne podstawy całej dziedziny. Podstawy te dają możliwość realizacji algorytmów eksploracji na rzecz badań wykonywanych w wybranej dziedzinie przez implementację aplikacyjną. Do technik eksploracji danych zalicza się:
— techniki predykcyjne,
— techniki deskrypcyjne,
— techniki uczenia nadzorowanego,
— techniki uczenia bez nadzoru.
Do metod eksploracji danych zalicza się:
— metody odkrywania asocjacji,
— metody klastrowania,
— metody odkrywania wzorców sekwencji reguł,
— metody odkrywania klasyfikacji,
— metody odkrywania podobieństw w przebiegach czasowych,
— metody wykrywania zmian i odchyleń,
— metody odkrywania cech.
Data mining a bazy danych
Pojęcie baz danych
Bazy danych są jedną podstawowych dziedzin informatyki o powszechnym zastosowaniu. Aktualnie systemy baz danych są wykorzystywane praktycznie w każdej dziedzinie — od hurtowni i sklepów, przez fabryki, instytucje państwowe, banki, różnego typu giełdy, poprzez zakłady naukowe i kończąc na zastosowaniach w wojsku. W każdym z tych miejsc mamy do czynienia z ogromnymi ilościami informacji i ich przetwarzaniem.
Współczesny świat jest tak zorganizowany, że ciężko jest znaleźć dobrze prosperującą firmę czy instytucję, która funkcjonowałaby bez posiadania mniej bądź bardziej zaawansowanego systemu bazodanowego.
Kup książkę, aby przeczytać do końca.